tl;dr: this plugin displays notes that are semantically similar to the one you are currently viewing, with similarity being determined by a neural network pre-trained on English words.
(please note that upon first install, it will immediately start encoding all of your notes into embeddings with the full processing power of your computer, which will probably make it unresponsive during this time. if you have a lot of notes, this can take a few minutes. if you have large notes (500+ kb of text), it might take a really long time.)
I find it immensely productive to link notes together as part of my writing/thinking process, but sometimes I am not able to remember all of the notes I have (I recently surpassed 1000 notes in my corpus), and it sometimes requires a flow-breaking hunt for specific notes when I do (eg if I know it exists but can't remember the name).
To help mitigate this, I've written a plugin that searches through my notes for other notes that are semantically similar. It ranks them according to how similar they are to the currently selected one, and links the most similar ones in a UI panel. I'd eventually really love the ability to have joplin automatically suggest notes that could be linked together. I consider this plugin a step towards that! Check out some screenshots:
Screenshot 1:
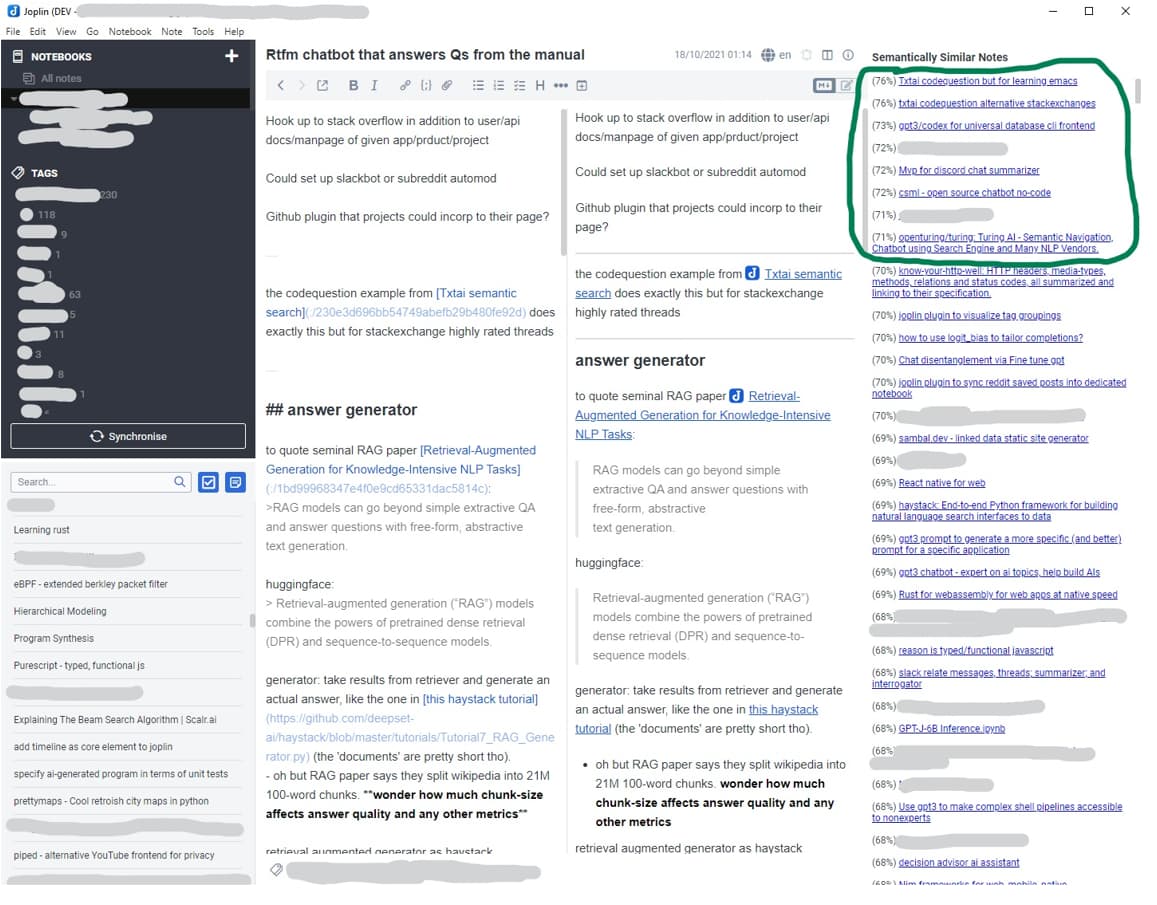
In this screenshot, I consider the notes within the green outline incredibly relevant to the note I'm working on. The other suggestions are also quite relevant, but less directly helpful.
Screenshot 2:

There isn't much to go off of in this note, but the model still finds relevant notes in my corpus via the title and url in the body. The top suggestion might be the only directly relevant one, but the others are still nice to be reminded of.
I've found this plugin increases my ability to iterate on and refine my "second brain" as a whole; the suggested ones are not so mentally distant (as determined artificially by a neural network), and therefore I don't need to context switch as much to consume and produce thoughts. It can actually feel a bit addicting at times to click through my lists of similar notes, add a blurb capturing how one /actually/ relates to another (or create a new note, linking both), and repeat!
As a bonus feature, this plugin can be used as a very crude semantic search (with really bad UI): create a note with your search query, select a different note and then select your newly created note -> see the most similar notes to your query. I don't really use it this way, and don't vouch for it's performance. I think better semantic search algorithms generally take into account the fact that the query size is very small compared to the size of each returned result.
The technology powering the semanticness is the Universal Sentence Encoder Lite model via tensorflow.js. I'd eventually like to experiment with other models, but this model is certainly sufficient for my current needs. From the USE lite tfjs github page: "The Universal Sentence Encoder (Cer et al., 2018) (USE) is a model that encodes text into 512-dimensional embeddings ... This [TensorFlow.js] module is a GraphModel converted from the USE lite module on TFHub, a lightweight version of the original. The lite model is based on the Transformer (Vaswani et al, 2017) architecture, and uses an 8k [English] word piece vocabulary."
It's available in the Joplin plugin repo (search in your joplin app for the name). And here's a link to the plugin source code: semantic-joplin/similar-notes at master · marcgreen/semantic-joplin · GitHub
At the time of posting this, I consider the plugin to be something like a beta version, as although there are a few obvious outstanding bugs/issues, there is enough functionality for it be useful in my own daily life. I'm tracking the full list of known bugs and potential features in the README (please read it before installing, especially if you have large notes), and I'd love to hear your feature requests, bug reports, and thoughts in general!





 (
(