GSoC 2026 Proposal Draft – Idea 1: AI-Supported Natural Language Search for Joplin
Links
- Project idea: https://joplinapp.org/gsoc2026/ideas/
- GitHub: dipanshurdev (Dipanshu Rawat) · GitHub
- Forum introduction: Welcome to GSoC 2026 with Joplin! - #58 by dipanshurdev
- Pull requests to Joplin:
- Other relevant experience:
- StudyOS AI – AI study platform I built using HuggingFace for automated note analysis and MCQ generation
- Portfolio
Introduction
I'm Dipanshu Rawat, a software developer from India with two years of professional experience building AI-powered products. At Vojic LLC I built VMeet, a real-time meeting assistant handling transcription and summarisation in production. Before that, at Claritel.ai, I integrated ML pipelines into a FastAPI/TypeScript backend, working daily with HuggingFace models and embedding-based retrieval systems.
I have been contributing to Joplin core since early 2026, working across UI state management, TypeScript utility optimisations, and localisation. Those five merged PRs gave me a working understanding of Joplin's plugin API, React layer, and internal data services, the exact areas this project touches.
For this proposal specifically, I read through filterParser.ts, SearchEngine.ts, and queryBuilder.ts before writing a single line. Every architectural decision below comes directly from that codebase reading, not from generic AI search literature.
Other Relevant Experience:
- StudyOS AI — AI study platform built using HuggingFace for automated note analysis and MCQ generation
- VMeet (Vojic LLC) — LLM-powered meeting assistant with real-time structured data extraction from free-form speech; the same extraction pattern used in this proposal's query translator
Project Summary
The Problem
Joplin's existing SQLite FTS5 engine is highly effective for exact keyword matches but cannot process conceptual queries or implicit metadata. A user who has spent years building a knowledge base has no way to ask it natural questions.
| What the user remembers | Keyword result | Why it fails |
|---|---|---|
| "Meeting with a German company in 2019 or 2020" | Zero results | Note says "Berlin client" not "German" or "meeting" |
| "Poetry lines about the moon" | Zero results | Note contains a haiku, the word "moon" never appears |
| "Tasks I wrote for the website redesign" | 50 results | Finds every note with "website", can't rank by intent |
| "That article about sleep and productivity" | Partial | Matches "productivity" but not the conceptual pairing |
| "My notes from the React conference last autumn" | Zero results | Note is titled "JSConf", date metadata isn't searched |
The Solution
This project builds a Hybrid Self-Querying Search Engine natively integrated into Joplin core. A single LLM call decomposes any natural language query into two parallel execution paths:
- Structured metadata filters (dates, tags, notebooks, types), compiled into
Term[]objects and passed intoqueryBuilder.tsusing Joplin's actual filter syntax - Semantic query string, embedded locally and searched against a vector store
Results from both paths are merged using Reciprocal Rank Fusion (RRF) and returned in the existing note list with an explainability badge showing how each note was found.
Input: "meeting with a German company in 2019 or maybe 2020."
Single LLM call → internal TranslatedQuery:
{
"filters": { "date_from": "20190101", "date_to": "20201231" },
"semantic_query": "meeting company client"
}
Query compiler step:
date_from/date_to → created:20190101 (Joplin YYYYMMDD format)
semantic_query → keyword slice passed to FTS + embedded for vector
→ FTS5 path: filterParser terms → queryBuilder SQL → filtered candidates
→ Vector path: embed("meeting company client") → semantic matches
→ RRF merge: notes scoring in both paths rank highest
→ Result badge: "date: 2019–2020 · semantic: meeting company"
What this is not: a replacement for Joplin's existing search. Every query that works today continues to work identically. The hybrid path is activated only when AI search is enabled and the query is clearly natural language.
Out of scope for v1.0: fine-tuning LLMs, indexing image or PDF attachments, mobile/web support.
Technical Approach
Codebase Grounding
Before designing anything, I traced the full search path in the codebase:
SearchEngine.search(query)
→ filterParser.parseQuery(query) // tokenises into Term[]
→ queryBuilder.buildQuery(terms) // emits SQL for notes_fts / notes_normalized
→ SQLite FTS5 query execution
→ SearchEngineUtils ranking / scoring
The relevant files:
packages/lib/services/search/
├── SearchEngine.ts ← orchestrator; calls parser, executes SQL, ranks results
├── filterParser.ts ← tokenises query string into Term[] objects
├── queryBuilder.ts ← converts Term[] into SQLite FTS5 SQL against notes_fts
└── SearchEngineUtils.ts ← frequency scoring, field weighting helpers
filterParser.ts accepts date values in Joplin's own formats: YYYYMMDD, YYYYMM, YYYY, or relative forms like day-1. It does not accept ISO strings like 2019-01-01. The getUnixMs helper in dateFilter handles this parsing. A date range in 2019–2020 compiles to:
created:20190101 created:20201231
// filterParser interprets:
// created:20190101 → notes created on or after 2019-01-01 (>=)
// -created:20201231 → negated upper bound gives < semantics
// or equivalent range approach confirmed with mentor during Community Bonding
This is the exact format the query compiler in this project will emit, not the raw JSON from the LLM.
Architecture Overview
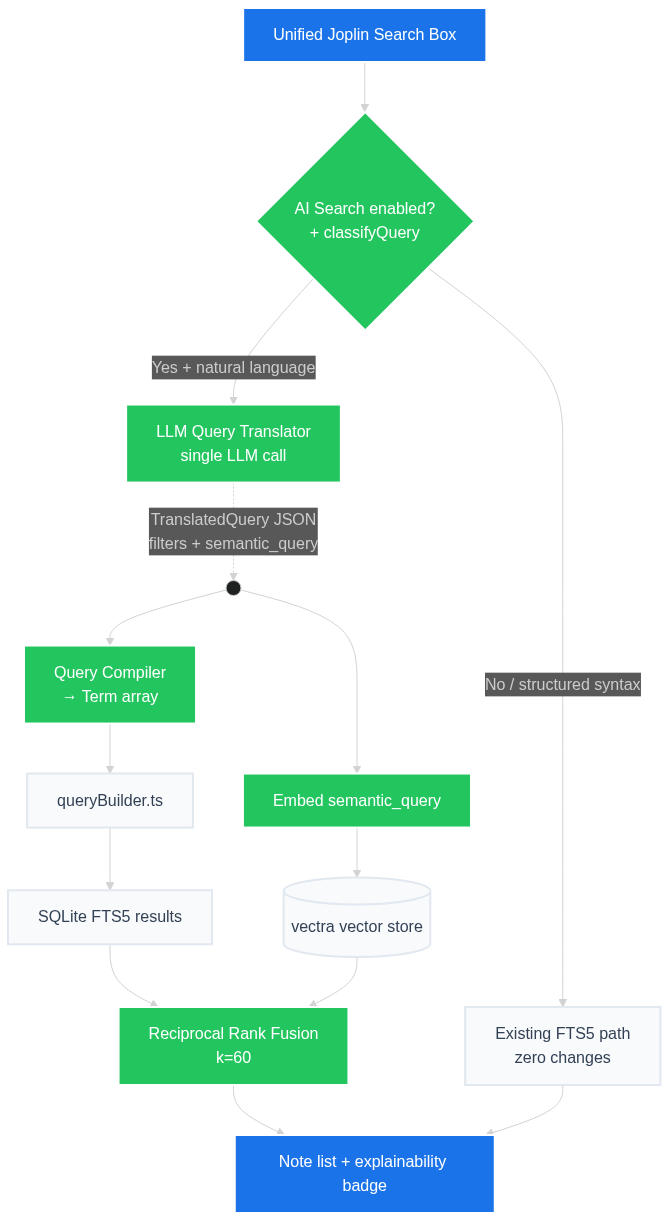
Why This Architecture Over Alternatives
| Approach | Problem |
|---|---|
| Pure agent loop (5 LLM tool calls) | Up to 5–15 seconds latency. Unacceptable for interactive search. |
| Pure embedding search | Blind to dates, tags, notebooks. "2019 or 2020" is invisible to vectors. |
| Pure LLM → FTS syntax | Misses conceptual queries where exact keywords are absent from the note. |
| Hybrid self-querying (this proposal) | One LLM call. Parallel execution. Metadata precision + semantic recall. |
Query Routing
The AI search path is only entered when:
- The user has AI search enabled in settings (opt-in), and
- The query does not contain explicit Joplin filter syntax
function shouldUseHybridSearch(query: string, aiEnabled: boolean): boolean {
if (!aiEnabled) return false;
// Pass through to existing engine if query uses Joplin filter syntax
const structuredPatterns = [
/^(any|title|body|tag|notebook|created|updated|type|iscompleted|due):/,
/^-?(any|title|body|tag|notebook):/,
/\bAND\b|\bOR\b|\bNOT\b/,
/^".*"$/,
];
return !structuredPatterns.some(p => p.test(query.trim()));
}
This replaces the "≤2 words = FTS" heuristic. The user can always type body:moon to force classic search regardless. Short conceptual queries like "moon haiku" or "Berlin meeting" correctly enter the hybrid path when AI is enabled.
Integration Point in SearchEngine.ts
Adding the hybrid path is a branch inside SearchEngine.search(), with the existing code path completely unchanged for all other cases:
// In SearchEngine.ts, new branch, old path untouched
async search(query: string, options: SearchOptions): Promise<SearchResult[]> {
if (shouldUseHybridSearch(query, this.aiSearchEnabled_)) {
return this.hybridSearch_(query, options);
}
// existing path, zero changes below this line
return this.searchFts_(query, options);
}
The existing searchFts_ method is not modified. No existing behaviour changes.
Component A, LLM Query Translator
A single LLM call converts natural language into an internal TranslatedQuery object. The LLM outputs abstract intent; a query compiler step converts this to Joplin's actual filter syntax before touching queryBuilder.ts.
// Step 1: LLM outputs abstract intent
const TRANSLATOR_PROMPT = `
You are a search query parser for a note-taking app.
Extract metadata filters and semantic intent from the user's query.
Return ONLY valid JSON. No explanation. No markdown.
Valid filter fields: date_from, date_to (YYYYMMDD integers), tag, notebook,
type ("note" or "todo"), keyword (optional residual keywords)
Example:
Input: "meeting with German company in 2019 or 2020"
Output: {"filters":{"date_from":20190101,"date_to":20201231},
"semantic_query":"meeting company client"}
`;
interface TranslatedQuery {
filters: {
date_from?: number; // YYYYMMDD integer, Joplin's actual format
date_to?: number; // YYYYMMDD integer
tag?: string; // value for tag: filter
notebook?: string; // value for notebook: filter
type?: 'note' | 'todo'; // value for type: filter
};
semantic_query: string;
}
// Step 2: Query compiler, converts TranslatedQuery → Term[] Joplin understands
function compileToJoplinTerms(tq: TranslatedQuery): string {
const parts: string[] = [];
if (tq.filters.date_from) parts.push(`created:${tq.filters.date_from}`);
// Upper bound uses negation for < semantics as queryBuilder supports
if (tq.filters.date_to) parts.push(`-created:${tq.filters.date_to}`);
if (tq.filters.tag) parts.push(`tag:${tq.filters.tag}`);
if (tq.filters.notebook) parts.push(`notebook:${tq.filters.notebook}`);
if (tq.filters.type) parts.push(`type:${tq.filters.type}`);
// Residual keyword slice for FTS text matching
if (tq.semantic_query) parts.push(tq.semantic_query);
return parts.join(' ');
// e.g. → "created:20190101 -created:20201231 meeting company client"
// This string is valid input to filterParser.parseQuery()
}
LLM Backends, unified LLMClient interface, user-configurable:
| Backend | What leaves the device | Speed | Status |
|---|---|---|---|
| Ollama (local) | Nothing — fully local | 1–3s | ✓ Default |
| OpenAI API (gpt-4o-mini) | Query text only, over HTTPS | < 1s | Optional |
| Anthropic API (claude-haiku) | Query text only, over HTTPS | < 1s | Optional |
| None configured | — | — | ✓ Graceful fallback to FTS5 |
Privacy note: In local mode (Ollama + local embeddings) no note content ever leaves the device. In cloud translation mode, only the user's query text is sent, not note content. Embeddings always run locally regardless of translation backend.
If the LLM returns malformed JSON, the system silently falls back to FTS5-only search, no crash, no broken UI.
Component B, Embedding & Vector Layer
All embedding runs locally regardless of which LLM backend is chosen for translation.
]

Embedding model: @xenova/transformers (Transformers.js) with BGE-small-en-v1.5 (24 MB, ONNX/WASM). This is a plausible path in Joplin's Electron environment, @xenova/transformers appears in Joplin's existing test/worker infrastructure. Final validation will happen in week 1 of Community Bonding with a minimal PoC; if WASM loading proves problematic in the production build, an alternative will be agreed with the mentor.
Vector store: vectra, pure TypeScript, zero native dependencies, file-backed JSON index:
| Option | Decision | Reason |
|---|---|---|
| vectra | ✓ Primary | Pure TypeScript. No native bindings. Cross-platform. Built-in BM25. Final choice subject to mentor review and bundle size assessment. |
| sqlite-vec | ✗ Not for v1 | C extension requiring native compilation. Incompatible with cross-platform builds. Could be revisited post-GSoC if maintainers accept native deps. |
| LanceDB / Chroma | ✗ Rejected | Require native binaries or a running server process. |
Incremental indexing, SHA-256 hashing skips unchanged notes; background indexing runs off the UI thread:
async function indexNote(note: JoplinNote): Promise<void> {
const hash = sha256(note.body).slice(0, 32);
const existing = await indexStateDb.get(note.id);
if (existing?.hash === hash) return; // unchanged, skip entirely
await vectorStore.deleteWhere({ noteId: note.id });
const chunks = chunkNote(note); // heading-aware, 400-token sliding window
const embeddings = await embedBatch(chunks.map(c => c.text));
await vectorStore.insertBatch(chunks, embeddings);
await indexStateDb.set(note.id, { hash, indexedAt: Date.now() });
}
Change detection: Joplin exposes note change events through its internal ItemChange tracking and SearchEngine.syncTables(). The indexer will hook into the same note-save paths that the existing search index uses, confirmed with mentor during Community Bonding. Periodic polling of updated_time covers bulk imports and sync arrivals.
Component C, Reciprocal Rank Fusion
Results from both paths are merged mathematically. A note ranking high in both paths scores higher than one dominating only one:
// Standard RRF: score = 1 / (rank + k), where k=60 is the accepted constant
function reciprocalRankFusion(
ftsResults: ScoredNote[],
vectorResults: ScoredNote[],
k = 60
): ScoredNote[] {
const scores = new Map<string, number>();
ftsResults.forEach((note, rank) => {
scores.set(note.id, (scores.get(note.id) ?? 0) + 1 / (rank + k));
});
vectorResults.forEach((note, rank) => {
scores.set(note.id, (scores.get(note.id) ?? 0) + 1 / (rank + k));
});
return [...scores.entries()]
.sort(([, a], [, b]) => b - a)
.map(([id]) => findNote(id, ftsResults, vectorResults));
}
Handling filters-only queries: When the LLM extracts only metadata filters with no semantic content (e.g. "notes from 2019"), semantic_query will be an empty string. In this case the vector leg is skipped and only the FTS5 path runs, avoiding a meaningless vector search against an empty embedding. The reverse (no filters, semantic only) runs vector search only, with FTS5 receiving a broad keyword slice of semantic_query as a secondary pass.
Component D, Explainability Badge
Each result in the note list shows how it was found. Built deterministically from the compiled query, no extra LLM call. The badge renders alongside existing search result rows in packages/app-desktop/gui/NoteList/:
function buildExplainBadge(tq: TranslatedQuery, path: 'fts' | 'vector' | 'both'): string {
const parts: string[] = [];
if (tq.filters.date_from) {
const from = String(tq.filters.date_from).slice(0, 4);
const to = String(tq.filters.date_to ?? '').slice(0, 4);
parts.push(`date: ${from}–${to}`);
}
if (tq.filters.tag) parts.push(`tag: ${tq.filters.tag}`);
if (tq.filters.type) parts.push(`type: ${tq.filters.type}`);
if (path !== 'fts') parts.push(`semantic: "${tq.semantic_query}"`);
return parts.join(' · ');
// → "date: 2019–2020 · semantic: meeting company"
}
Worked Examples
"Meeting with a company from Germany in 2020 or maybe 2019"
LLM output: { filters: { date_from: 20190101, date_to: 20201231 },
semantic_query: "meeting company client" }
Compiler: "created:20190101 -created:20201231 meeting company client"
→ valid filterParser.parseQuery() input
FTS5 path: date-filtered SQL → candidates in 2019–2020 range
Vector path: embed("meeting company client") → semantic matches
RRF merge: "Berlin client sync call – Jan 2020" ranks 1 (in both paths)
Badge: "date: 2019–2020 · semantic: meeting company"
"List of tasks I wrote for the website redesign"
LLM output: { filters: { type: "todo" },
semantic_query: "website redesign tasks checklist" }
Compiler: "type:todo website redesign tasks checklist"
FTS5 path: type:todo filter → to-do notes only
Vector path: embed("website redesign tasks") → semantic matches
Badge: "type: todo · semantic: website redesign"
"Poetry lines about the moon"
LLM output: { filters: {}, semantic_query: "poetry moon verse night" }
Compiler: no filter terms → semantic_query used as keyword slice for FTS
FTS5 path: keyword search → 0 results (word "moon" absent from note text)
Vector path: embed("poetry moon verse night") → haiku surfaces via semantic proximity
Badge: "semantic: poetry moon verse"
Threat Model & Operational Risks
| Risk | Detail | Mitigation |
|---|---|---|
| Encrypted notebooks | vectra index stored in joplin.plugins.dataDir() (or equivalent core path), separate from sync |
Index never synced; re-built locally on each device |
| First-time index cost | 10,000 notes × embedding time could be minutes | Background worker with progress bar; search still works via FTS5 during initial build |
| Background CPU on battery | Continuous embedding worker drains battery | Idle-only scheduling; pause on battery (configurable) |
| Large vault memory | vectra loads full index (~75 MB for 10k notes) | Configurable chunk limit; mentor review on final threshold |
| LLM unavailable | Ollama not running; API key missing | Silent fallback to FTS5; one-time settings notice |
UI Integration
| Query type | Indicator | Engine |
|---|---|---|
| AI Search disabled (default off until configured) | None — identical to today | Existing FTS5 |
AI Search enabled + structured syntax (tag:work) |
None — passes through | Existing FTS5 |
| AI Search enabled + natural language | Animated ✦ AI badge while translating |
Hybrid search |
| LLM unavailable | One-time settings notice | FTS5 fallback |
New settings under Tools → Options → Search:
| Setting | Default | Purpose |
|---|---|---|
| AI Search: enabled | false | Opt-in toggle, off until user configures an LLM |
| AI Search: LLM backend | Ollama | Local or cloud LLM selection |
| AI Search: endpoint / API key | http://localhost:11434 | Ollama URL or cloud API key |
| AI Search: show explainability badge | true | Show/hide result annotations |
Potential Challenges & Mitigations
| Challenge | Mitigation |
|---|---|
| Transformers.js WASM in Electron/Webpack | PoC in Community Bonding week 1. @xenova/transformers appears in Joplin's existing worker infrastructure, validate production build path before committing. |
| Date filter upper bound semantics | queryBuilder.ts uses negated created: for < semantics. Exact range pattern confirmed with mentor / codebase reading before Phase 2. |
| vectra memory on large vaults | Configurable chunk limit. Idle-only background loading. Final bundle size reviewed with mentor. |
| LLM translation latency | Loading indicator shown immediately. FTS5 path returns near-instantly in parallel. |
| Malformed JSON from LLM | Strict schema validation with zod or equivalent. On failure: silent FTS5 fallback. |
| Empty semantic query / filters-only | Skip vector leg; run FTS5 with compiled filter terms only. |
| Core vs plugin integration | Architecture is identical either way. Confirm preferred integration point with @malekhavasi in Community Bonding week 1. |
Implementation Plan
Total: 350 hours across 14 weeks + Community Bonding
Community Bonding (May 4 – May 26)
- Confirm integration point (core vs plugin) with @malekhavasi
- Read
queryBuilder.tsgenericFilter+dateFilterend-to-end; confirm exact date range syntax - Validate
@xenova/transformersWASM loading inside Joplin's Electron/Webpack build with a minimal PoC - Confirm note change event hook approach with mentor (
ItemChange/syncTablespath) - Prototype the LLM translator with a 10-query smoke test against real Joplin notes
- Build small labelled query set (aim for ~30–50 queries) as initial evaluation baseline
Phase 1 — Embedding & Vector Indexing (May 27 – Jun 24) · ~100 hrs
| Week | Tasks |
|---|---|
| Week 1 | Heading-aware chunking, 400-token sliding window fallback, merge tiny chunks; unit tests |
| Week 2 | @xenova/transformers BGE-small-en-v1.5 in background worker; WASM loading in production build |
| Week 3 | vectra integration; metadata filters (notebook, tag, type); CRUD pipeline; index stored in core data dir |
| Week 4 | SHA-256 change detection; note-save hook via Joplin's ItemChange / syncTables; periodic polling for bulk imports |
Phase 2 — LLM Query Translator & Compiler (Jun 25 – Jul 15) · ~75 hrs
| Week | Tasks |
|---|---|
| Week 5 | LLMClient interface; Ollama backend; system prompt engineering; zod JSON schema validation + fallback |
| Week 6 | OpenAI and Anthropic API backends; unified swappable interface; settings API key integration |
| Week 7 | compileToJoplinTerms() query compiler; shouldUseHybridSearch() router; full integration with SearchEngine.search() |
Phase 3 — Hybrid Execution & RRF (Jul 16 – Aug 5) · ~75 hrs
| Week | Tasks |
|---|---|
| Week 8 | Compiler output → filterParser.parseQuery() → queryBuilder.ts FTS5 path; date range validation |
| Week 9 | Parallel execution of both paths; RRF merger; filters-only / semantic-only edge case handling |
| Week 10 | Explainability badge in note list UI (packages/app-desktop/gui/NoteList/); progress indicator in search bar |
Phase 4 — Settings, Testing & Docs (Aug 6 – Sep 1) · ~100 hrs
| Week | Tasks |
|---|---|
| Week 11 | Settings panel (enable toggle, backend selector, API key/endpoint, badge toggle); opt-in default |
| Week 12 | Evaluation against labelled query set, Hit@3 and MRR vs FTS5 baseline |
| Week 13 | Large vault testing (10,000+ notes); latency profiling; first-time index UX; regression pass |
| Week 14 | User documentation; developer guide for adding LLM backends; PR cleanup; merge |
Deliverables
| # | Deliverable | Description |
|---|---|---|
| 01 | Query Router | shouldUseHybridSearch(), opt-in gate with structured syntax passthrough. |
| 02 | LLM Query Translator | Single-call JSON extractor. Ollama, OpenAI, Anthropic backends behind a unified LLMClient interface. |
| 03 | Query Compiler | compileToJoplinTerms(), converts TranslatedQuery to valid filterParser input using Joplin's actual date/filter syntax (YYYYMMDD). |
| 04 | Embedding Indexer | BGE-small-en-v1.5 via @xenova/transformers WASM. Heading-aware chunking. SHA-256 incremental change detection. Background worker. |
| 05 | vectra Vector Store | Pure-TypeScript local index. No native dependencies. Metadata filtering. Built-in BM25. |
| 06 | Hybrid Executor | Parallel FTS5 + vector execution. Handles filters-only and semantic-only edge cases. Result deduplication. |
| 07 | RRF Merger | Mathematically merges ranked lists using standard k=60 constant. |
| 08 | Explainability Badge | Deterministic result annotation in note list UI. No extra LLM call. |
| 09 | Settings UI | Opt-in enable toggle, backend selector, API key/endpoint config, badge toggle. |
| 10 | Documentation | User guide; developer guide for adding LLM backends; inline code docs throughout. |
Availability
| Hours per week | 40–45 |
| Timezone | IST (UTC+5:30) |
| Competing commitments | None, no conflicting internships or jobs during GSoC |
| College coursework | Will not affect committed GSoC hours |
| Communication | Weekly progress updates on the Joplin forum; available on Discord throughout |
AI Assistance Disclosure
I used Claude (Anthropic) as an AI tool during the preparation of this proposal.
What AI was used for:
- Drafting and structuring proposal sections based on my technical research
- Improving clarity and wording of explanations I had already reasoned through
- Formatting tables, code block layout, and section organisation
What AI was NOT used for:
- The codebase research. I read
filterParser.ts,SearchEngine.ts, and
queryBuilder.tsdirectly and verified all technical details (YYYYMMDD date
format,ItemChange/syncTableshooks,vectravssqlite-vecconstraint)
myself before any drafting began - The architectural decisions. The choice of hybrid self-querying over agent loops,
theshouldUseHybridSearch()routing logic, and thecompileToJoplinTerms()
compiler step came from my own analysis of the codebase and the forum discussion
Confirmation:
- I have reviewed the entire proposal carefully
- I understand every piece of code and every architectural decision in it
- I can explain and justify any section in a live discussion